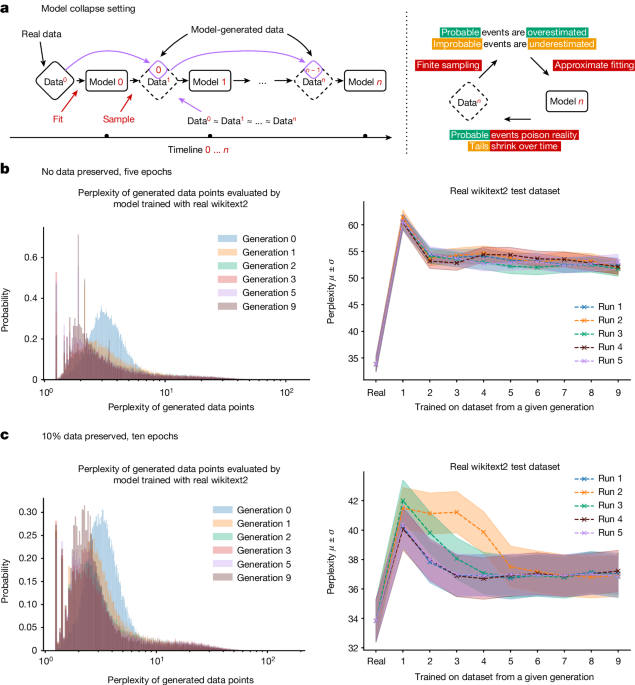
Analysis shows that indiscriminately training generative artificial intelligence on real and generated content, usually done by scraping data from the Internet, can lead to a collapse in the ability of the models to generate diverse high-quality output.
Yeah! That’s one of my favorite things to talk about when mentioning A.I.!
Scraping images from the Internet is pretty bad, especially if you get more A.I. generated images than “real” ones, because A.I. always makes tiny mistakes. If it learns from an image made from an artist, it’ll incorporate characteristics from that artist, but with a tiny amount of “mistakes”, in order to make it sort of unique. However, if it learns from an image made from another A.I. (or itself even), it’ll not only incorporate the mistakes that the first A.I. made, but also add mistakes of its own.

Yeah! That’s one of my favorite things to talk about when mentioning A.I.!
Scraping images from the Internet is pretty bad, especially if you get more A.I. generated images than “real” ones, because A.I. always makes tiny mistakes. If it learns from an image made from an artist, it’ll incorporate characteristics from that artist, but with a tiny amount of “mistakes”, in order to make it sort of unique. However, if it learns from an image made from another A.I. (or itself even), it’ll not only incorporate the mistakes that the first A.I. made, but also add mistakes of its own.