
1·
5 days agoCaddy manages everything, including certs for both domains. So I guess my answer would be, you don’t.
Caddy manages everything, including certs for both domains. So I guess my answer would be, you don’t.
Caddy does not need 80 and 443.
By default and all measurable expectation it does. Unless you can’t use privileged HTTP/HTTPS ports, there’s no real reason to use unprivileged ports.
Besides, op doesn’t mention having problems with ports
OP said he was having issues, and this is a common issue I’ve had. Since he was non-descript as to what the issues were, it’s really not stupid to mention it.
Well that’s dope… Didn’t know that was a thing.
The biggest issue I have with Caddy and running ancillary services as some services attempt to utilize port 80 and/or 443 (and may not be configurable), which of course isn’t possible because Caddy monopolizes those ports. The best solution to this I’ve found is to migrate Caddy and my services to docker containers and adding them all to the same “caddy” network.
With your caddy instance still monopolizing port 80 and 443, you can use the Docker expose or port parameters to allow your containers to utilize port 80 and/or 443 from within the container, but proxify it on the host network. This is what my caddy config looks like;
{
admin 127.0.0.1:2019
email {email}
acme_dns cloudflare {token}
}
domain.dev, domain.one {
encode zstd gzip
redir https://google.com/
}
*.domain.dev, *.domain.one {
encode zstd gzip
@book host bk.domain.dev bk.domain.one
handle @book {
reverse_proxy linkding:9090
}
@git host git.domain.dev git.domain.one
handle @git {
reverse_proxy rgit:8000
}
@jelly host jelly.domain.dev jelly.domain.one
handle @jelly {
reverse_proxy {ip}:8096
}
@status host status.domain.dev status.domain.one
handle @status {
reverse_proxy status:3000
}
@wg host wg.domain.dev wg.domain.one
handle @wg {
reverse_proxy wg:51820
}
@ping host ping.domain.dev ping.domain.one
handle @ping {
respond "pong!"
}
}
It works very well.
It’s likely illegal. The administration would call it theft of service because it’s not authorized and they wouldn’t be wrong. I also don’t see why you would want to do it. You’re giving the IT department at your school complete access to your web history.

It’s zipping a zip file. Endlessly re-compressing things doesn’t yield positive results in the way you describe.
Blu-rays are compressed.
All streaming data is compressed at some point. I clearly meant not over-compressed. 4K video or UHD BD can both be taken from their original states and processed through HEVC to get crisp 1080p h265 10bit at a steep data discount. But it’ll take a very long time to process. It’s simply not worth it.
“Zipping a zip file” doesn’t apply here because zips are lossless.
It’s a figurative expression and I feel that was pretty damn obvious…
I’m confused… Are you grabbing pirated video files from the net and re-encoding them… If you’re attempting to further compress already compressed video, you’re just zipping a zip file. It’s crazy and you’ll do nothing but bloat the file size (versus a properly compressed video file) and further reduce the quality of the video via artifacts. I’ll call the police and have you committed right now.
If you’re grabbing 8/4k or UHD BD movies and re-encoding them into lets say, 1080p HEVC 10bit, I could see that being worth it if you really love the movie (and have 5 days with nothing to do), but only if you’re going from an inferior compression to better (h264 to h265), otherwise like I said, you’re zipping a zip file.
Because it has integrations for The Internet Archive: https://x0.at/Wny_.png
It says “local html” but I have a feeling it simply grabs a copy from the internet archive. I can’t even find where its storing these copies with it enabled.
There is. wget doesn’t follow recursive links by default. If it is, you’re using an option which is telling it to…
It does neither. It doesn’t create snapshots of pages at all… It’s a bookmark manager.
https://linkding.link/ is what you’re looking for.
Use the bookmarklet or FF/Chrome extension on a page and it saves it to your server to look at later. Add tags, folders, whatever. You can setup newly added links to be un-archived, and old links to be archived, or basically however you want.
That’s not a bug. You literally told wget to follow links, so it did.
restic restore --dry-run
Great work man. That’s really the only thing that I’ve found to gripe about. Other than that it was a simple setup and configuration. I particularly like that you hold my hand when changing things like the font. Such a subtle but cool change to add some individuality to it.
Great tool. I just pushed it to production for all my projects.
Whatever shows up here: https://newtrackon.com/list
Only lists trackers submitted that are online with a 95% uptime.
Just like I told you in the other thread, there’s no application which exists to clone files which are private to the webserver, like most dynamic content.
You can perfectly clone 1:1 public and static files. You can grab media like images, javascript, ajax, even videos. But you cannot grab the inner-workings of a website and somehow make them work, like php scripts or any other compiled languages, database connections, etc.
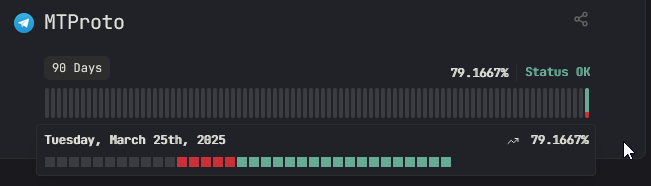
Doesn’t support docker host names, which is a bummer. You have to use IPv4/6 and the docker IP for services to work correctly. The service setup is also a bit weird. You can’t seem to delete a service once it’s been made. You can only “hide” it. So I just set this up, and mistyped an IP, and now I have a service with only 70% uptime because the first few pings failed due to the mistyped IP. (https://x0.at/ZvM1.png) There doesn’t seem to be a way to reset the uptime, or delete the monitor. You actually have to rename the service monitor to something random, and “hide” it, then remake your service like new.
Seems weird.
Nice dashboard though.
{kind=link}
{kind=link}
About the best you can do.