TS is a lot easier to set up than WG and does not require a publicly accessible IP address nor any public whatsoever. It’s not really comparable to setting WG up yourself; especially w.r.t. security.
Atemu
Interested in Linux, FOSS, data storage systems, unfucking our society and a bit of gaming.
I help maintain Nixpkgs.
https://github.com/Atemu
https://reddit.com/u/Atemu12 (Probably won’t be active much anymore.)
- 5 Posts
- 411 Comments
Joined 4 years ago
Cake day: June 25th, 2020
You are not logged in. If you use a Fediverse account that is able to follow users, you can follow this user.
It’s a central server (that you could actually self-host publicly if you wanted to) whose purpose it is to facilitate P2P connections between your devices.
If you were outside your home network and wanted to connect to your server from your laptop, both devices would be connected to the TS server independently. When attempting to send IP packets between the devices, the initiating device (i.e. your laptop) would establish a direct wireguard tunnel to the receiving device. This process is managed by the individual devices while the central TS service merely facilitates communication between the devices for the purpose of establishing this connection.
If you’re worried about that, I can recommend a service like Tailscale which does not require permanently open ports to the outside world, offering quite a bit more security than an exposed traditional VPN server.

 16·3 months ago
16·3 months agoOh I’m sure your health insurance would love to know the condition of your teeth to increase your rates.
 5·3 months ago
5·3 months agoYes, yes they will. If you’re the sole user, they’d identify you from your behaviour anyways.
I don’t think internet proxy won’t help very much w.r.t. privacy but it will make you a lot more susceptible to being blocked.
Thank you for your thoughts, I really enjoyed reading them :)
This reads like a phrase from Half as Interesting.
 1·3 months ago
1·3 months agoI don’t like the Piped bot at all.
What should be posted on the internet should be the canonical source of some content, not a proxy for it. If users prefer a proxy, they should configure their clients to redirect to the proxy. Piped instances come and go and the entire project is at the mercy of Google tolerating it/not taking action against it, so it could be gone tomorrow.
I use piped myself. I have client-side configurations which simply redirects all Youtube links to my piped instance. No need for any bots here.
This would better be done in the front-end rather than a comment bot.
That does not address the point made. It doesn’t matter whether it’s a complex hardware or software component in the stack; they will both fail.
 2·3 months ago
2·3 months agoIs “Grouped Results” disabled in settings?
 3·3 months ago
3·3 months agoCertainly better than the U.S. in that regard but I wouldn’t consider Germany “resilient” either.
Whether this is bad depends on your threat model. Additionally, you must also consider that other search engines are able to easily identify you without you explicitly identifying yourself. If you can’t fool https://abrahamjuliot.github.io/creepjs/, you certainly can’t fool Google for instance. And that’s even ignoring the immense identifying potential of user behaviour.
Billing supports OpenNode AFAICT which I guess you could funnel your Moneros through but meh.
Edit: Phrasing.
I think you’re underestimating how huge of an undertaking a half-decent search index is, much less a good one.
I personally have not found Kagi’s default search results to be all that impressive
At their worst, they’re as bad as Google’s. For me however, this is a great improvement over using bing/Google proxies which would be the alternative.
maybe if I took the time to customize, I might feel differently.
That’s the killer feature IMHO.
Your search results look very different to mine:
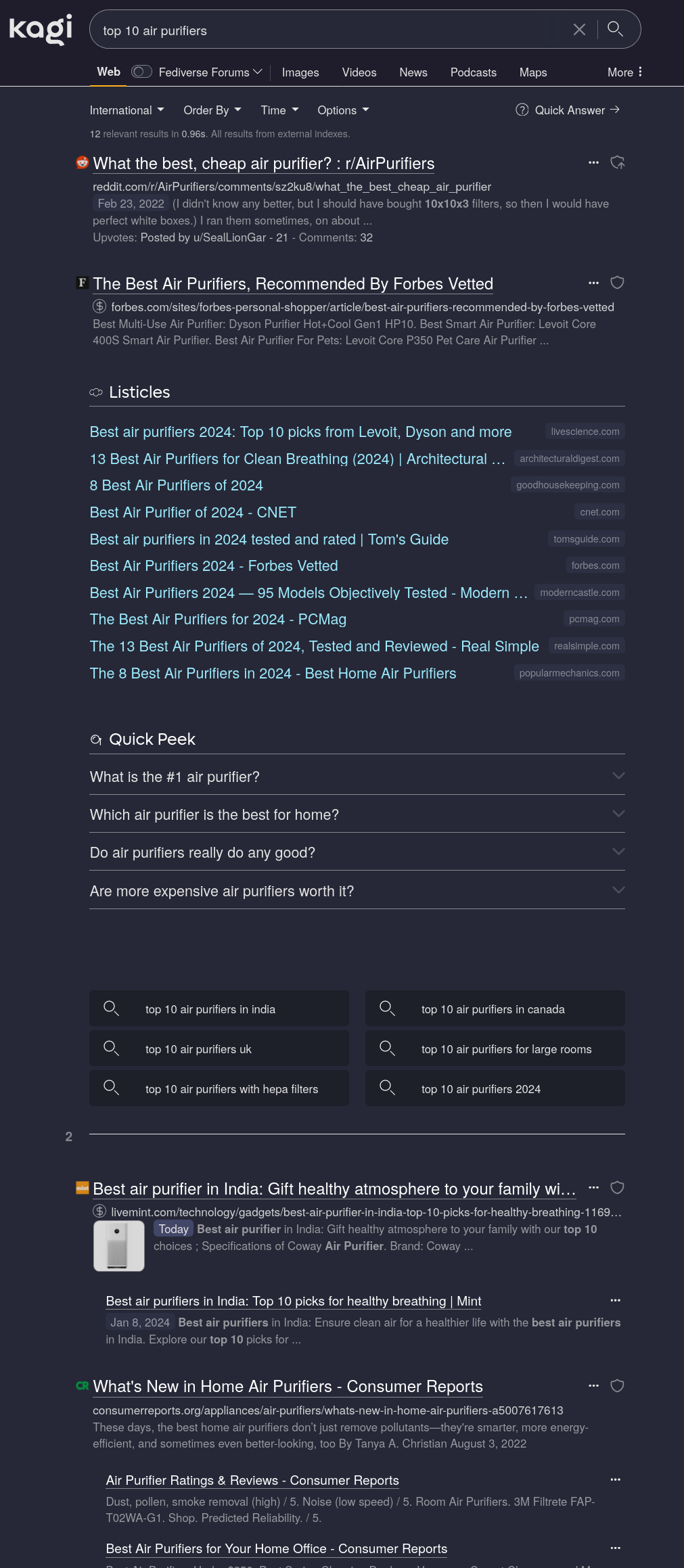
Did you disable Grouped Results?
All the LLM-generated “top 10” listicles are grouped into one large block I can safely ignore. (I could hide them entirely but the visual grouping allows for easy mental filtering, so I haven’t bothered.) Your weird top10 fake site does not show up.
But yes, as the linked article says, Kagi is primarily a proxy for Google with some extra on top. This is, unfortunately, a feature as Google’s index still reigns supreme for general purpose search. It absolutely is bad and getting worse but sadly still the best you can get. Using only non-Google indices would just result in bad search results.
The Google-ness is somewhat mitigated by Kagi-exclusive features such as the LLM garbage grouping.What Google also cannot do is highlighted in my screenshot: You can customise filtering and ranking.
The first search result is a Reddit thread with some decent discussion because I configured Kagi to prefer Reddit search results. In the case of household appliances, this doesn’t do a whole lot as I have not researched trusted/untrusted sources in this field yet but it’s very noticeable in fields like programming where I have manually ranked sites.Kagi is not “all about” privacy. It’s a factor, sure but ultimately you still have to trust a U.S. company. Better than “trusting” a known abuser (Google, M$) but without an external audit, I wouldn’t put too much wight into this.
The index ain’t it either as it’s mostly Google though sometimes a bit better.
What really sets it apart is the features. Customised ranking aswell as blocking some sites outright (bye bye pinterest and userbenchmark) are immensely useful. So are filtering garbage results that Google still likes to return.
That whole situation was such an overblown idiotic mess. Kagi has always used indices from companies that do far more unethical things than committing the extreme crime of having a CEO who has stupid opinions on human rights.
I 100% agree with Vlad’s response to this whole thing and anyone who thinks otherwise should question what exactly it is they’re criticising.I don’t like Brave (super shady IMHO) and certainly not their CEO but I didn’t sign up for a 100% ethically correct search engine, I signed up for a search engine with innovative features and good search results. The only viable alternatives are to use 100% not ethically correct search indices with meh (Google) to bad (Bing, DDG) search results. If you’re going to tell me how Google and M$ are somehow ethical, I’m going to have to laugh at you.
The whole argument amounts to whining about the status quo and bashing the one company that tries anything to change it. The only way to get away from the Google monopoly is alternative indices. Yes those alternatives may not be much more ethical than friggin Google. So what.
 0·3 months ago
0·3 months agoNo, they’ve got the same information as us. That’s why they explicitly say:
when Covid pandemic lockdowns and social distancing appeared to have halted circulation
It is still speculation, not data.
I’d tend to agree with the speculation but it’s still speculation.
I consider those measures to be included in “lockdown” but it’s besides the point: The paper contains no evidence that those measures made it disappear, just that it disappeared.




;)